Advanced tips to optimize C++ codes for computer vision (III): Parallel Processing
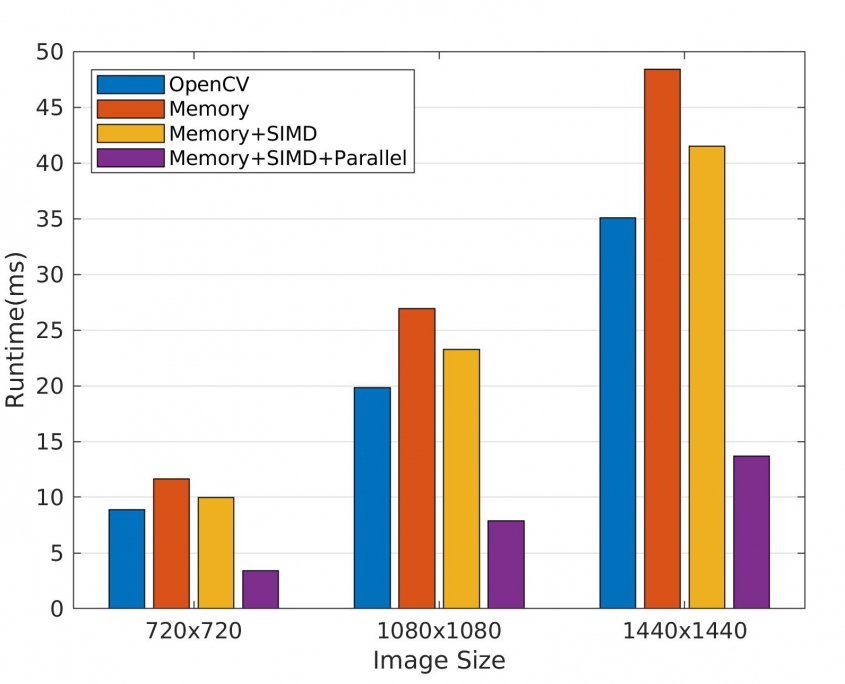
Multicore processing was a paradigm shift in computer science. The move was such big that today its really hard to find single-core CPUs even on low power SBCs. Computer vision algorithms, from simple pixel manipulations to the more complex tasks like classification with deep neural networks, have the potential to run parallel on multi cores. In this post, we will see how to easily parallelize the Gaussian-blur function that we implemented in the previous post. Our code will run almost 3x faster than the single-threaded version.
1. The Concept
Suppose that our CPU has a single core and the user wants to browse the web while listening to music. We define 2 threads. One for the browser and the other for the media player. The CPU works on thread#1 for 2ms, then switches to thread#2 for 5ms, and then switches back to thread#1 for 1ms. These switches are so fast that the user doesn’t feel any lag. Everything seems to work in parallel but it’s sequential in nature. This is called multi-threading.
What if the CPU had 2 cores? Then we could define thread#1 in core#1 and thread#2 in core#2, working parallel in nature. One of the threads becomes the master thread and controls the other thread in terms of locking, joining, data sharing, and other stuff. This is called multi-processing, or parallel processing.
In this example, listening to music is completely separate from browsing the web. That’s the key assumption in parallel processing. You can accelerate a slow for-loop by assigning each core to do a portion of the iterations if and only if the iterations are independent of each other.
2. OpenMP
You can define threads in C++11 without any external libraries. But the community has built several libraries and tools to simplify the process. OpenMP is one of these tools which makes parallel processing super-easy. Unlike other tools (MPI and pthreads), you don’t have to change your code. All you need is to add some pragma directives to the code. That’s why I like it. Minimum change to code, significant boost in runtime! See dot-product implementations in different versions.

Obviously, the OpenMP version is much more readable and maintainable. But what if someone runs the code on a single-core CPU? The compiler will automatically ignore pragma directives and the code will run single-threaded. BAM!
3. Pragmas and their usage
OpenMP provides a set of directives and so-called clauses that you must learn well. Otherwise, your code will probably run even slower than the single-threaded version! These pragmas are available when you #include . They always start with #pragma omp, followed by a specific keyword that identifies the directive, with possibly one or more clauses, each separated by a comma. These clauses are used to further specify the behavior or to further control parallel execution.
#pragma omp directive-name [clause[[,] clause]. . . ] new-line
For example in the following code, #pragma omp parallel for num_threads(2) forces OpenMP to run the for-loop with 2 threads. If num_threads is not set, the for-loop will run with the default number of the threads (equal to the number of the CPU cores).
#pragma omp parallel for num_threads(2)
for (unsigned int i = 0; i <= n; i++ )
{
c[i] = a[i]*b[i];
}
By default, OpenMP considers the variables in the code block to be shared among all the threads. If there is a variable that must be private to each core, use private keyword.
#pragma omp parallel for private(sum)
for (unsigned int i = 0; i <= n; i++ )
{
sum = a[i]*b[i];
c[i] = sum+2; //Ridiculously useless! Just to show the usage of 'private'
}
If there is a variable that has dependency with previous iterations, use reduction keyword to exclude it from parallelism.
#pragma omp parallel for reduction(+:sum)
for (unsigned int i = 0; i <= n; i++ )
{
sum = sum + a[i]*b[i];
}
By default, OpenMP assigns equal iterations to the threads. Given 100 iterations and 4 cores, each core will handle 25 iterations. That seems OK. But what if the overhead of the iterations would not be equal? For example, when a function is applied to layers of an image pyramid, the first iterations would be heavier than the last ones because first layer images are bigger than the last ones. In such situations, equal distribution of the iterations doesn’t effectively reduce the runtime. One core will be busy processing big images, while other cores have already processed their small images waiting idle for the busy core to finish its job. The solution is to set the schedule keyword to runtimeor dynamic instead of static (default value).
#pragma omp parallel for schedule(runtime)
for (unsigned int i = 0; i <= n; i++ )
{
for (unsigned int j=0; j<i;j++) //Very weird!! Just to show non-uniform load of iterarions
{
c[j]+=a[i]*b[i];
}
}
OpenMP is not used only for for-loops. You can parallelize the execution of custom sections of your codes by the section keyword:
#pragma omp sections
{
#pragma omp section
{
for (unsigned int i = 0; i <= n; i++ )
c[i] = a[i]*b[i];
}
#pragma omp section
{
for (unsigned int i = 0; i <= n; i++ )
d[i] = a[i]*b[i];
}
}
The above directive and clauses are the ones that I have used myself in my projects. There are more keywords to further control the behavior of parallel execution. If you are interested, check this link.
4. Gaussian-Blur
Let’s test OpenMP in real and see how it can boost execution time.
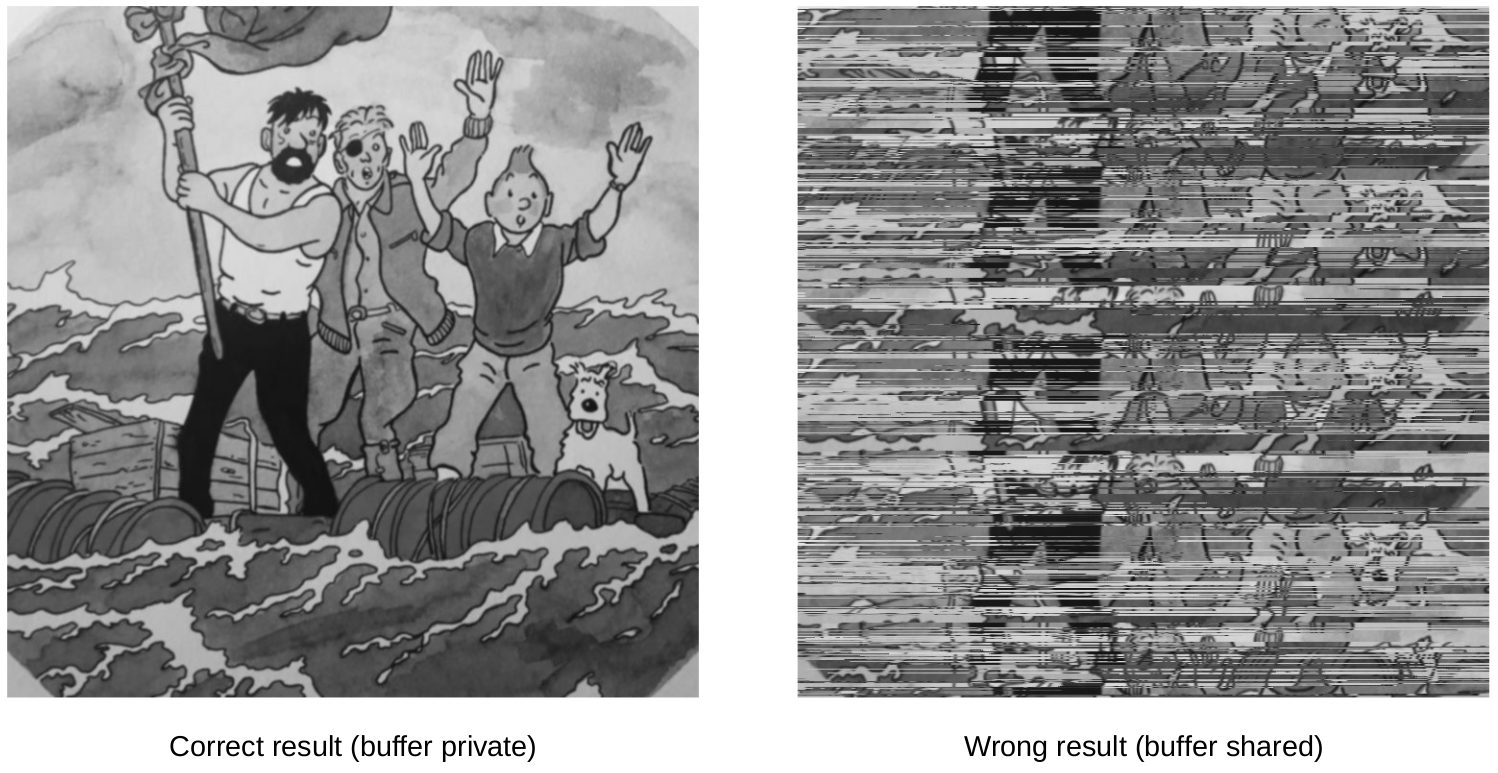
Our memory-efficient and vectorized implementation of Gaussian-blur can be further accelerated by parallel processing because the pixel-values of each row of the blurred image does not depend on previous rows. All we need is to add a #pragma omp parallel for. We define the buffer to be private among the cores. Otherwise, different cores that work on separate rows, write to the same buffer which makes the output wrong. Compile the code with -fopenmp and see the gain with different image resolutions.
//Middle rows
#pragma omp parallel for private(buffer)
for (unsigned int i=2; i<rows-2; i++)
{
unsigned int j=0;
for (; j<cols; j+=4)
{
cv::v_float32x4 a = cv::v_load_aligned(&input.val[i-2][j]);
cv::v_float32x4 b = cv::v_load_aligned(&input.val[i-1][j]);
cv::v_float32x4 c = cv::v_load_aligned(&input.val[i ][j]);
cv::v_float32x4 d = cv::v_load_aligned(&input.val[i+1][j]);
cv::v_float32x4 e = cv::v_load_aligned(&input.val[i+2][j]);
cv::v_float32x4 result = ((a+e)*coef1) + ((b+d)*coef2) + (c*coef3);
cv::v_store_aligned(&buffer[j], result);
}
//leftovers
for (; j<cols; j++)
buffer[j] = (input.val[i-2][j]+input.val[i+2][j])*0.054488685f + (input.val[i-1][j]+input.val[i+1][j])*0.24420135f + input.val[i][j]*0.40261996f;
GaussianBlur_row(buffer, output.val[i], cols);
}
5. Summary
- Today, almost all CPUs are multi-core. If you have separate blocks of code (with no dependency), consider parallelizing them to significantly boost the runtime.
- OpenMP provides an easy way to parallelize your code with minimum change. All you need is to learn its directives and use them correctly.
6. Further read
Chapman, B., Jost, G., & Van Der Pas, R. (2008). Using OpenMP: portable shared memory parallel programming (Vol. 10). MIT press.
Related Posts:
- Advanced tips to optimize C++ codes for computer vision tasks (II): SIMD
- Advanced tips to optimize c++ codes for computer vision tasks (I): Memory Management
- Simple tips for optimizing C++ codes
- Transfer learning for face mask recognition using libtorch (Pytorch C++ API)
- Image classification with pre-trained models using libtorch (Pytorch C++ API)
Leave a Reply
Want to join the discussion?Feel free to contribute!