Become an embedded computer vision engineer
Being an embedded computer vision engineer has been my first goal in the last couple of recent years. It all raised from my interest to image processing and the thirst for running codes faster and faster! Now after 7 years, when I look back and compare myself with the early days, I see lots of things that worth sharing. In this post, I will try to shed some light on how to start this path, get good jobs, and remain updated in this fast-changing branch of engineering.
Why should I guide people that might become my competitor?
As I will explain later, being an embedded computer vision engineer requires watching hundreds of hours of videos and reading thousands of pages of tutorials, papers, and books. This will NEVER happen without passion and interest. And if you have such a passion, then neither I nor any other guy can stop you. Reading this post just helps you to walk easier. After all, we all learn from each other. The open-source mindset is the only fair way we can grow.
Who is called an embedded computer vision engineer?
A person who can make computer vision applications on embedded processors is called an embedded computer vision engineer! This simple definition, however, brings lots of challenges with itself. To be the wanted guy:
- You must have a general understanding of both geometric and semantic areas of computer vision
- You must be a good C++ coder with some experience in Python or Matlab
- You must have a good understanding of the architecture of different processors and cameras
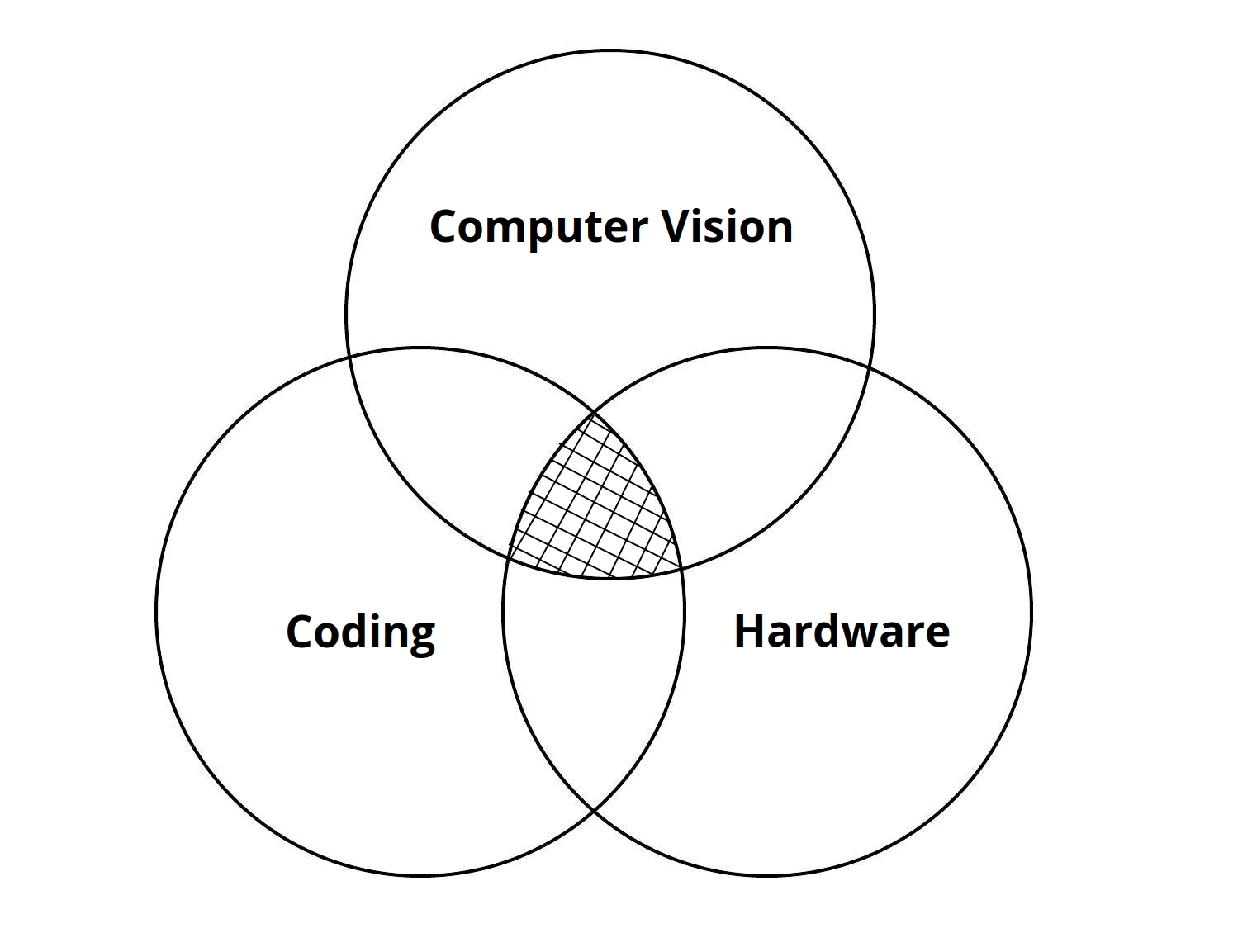
So, in short, embedded computer vision is the intersection of computer vision, coding, and hardware. In the rest of the post, I will explain each one of these domains separately and introduce good resources to start learning them.
Computer Vision
Cameras are one of the best sensors to add intelligence to an agent. They are small, light-weight, and affordable sensors with low power consumption that can be found in many devices (phones, tablets, and drones). Computer vision is the set of theories and algorithms to measure geometry, or to make semantic inferences of the environment from the camera data. The geometric branch, which is also called Photogrammetry, deals with applications like camera calibration, 3D reconstruction of the environment, Visual-SLAM, Visual-Odometry, and, depth and pose estimation. The semantic branch, on the other hand, deals with applications like image classification, segmentation, object detection, and object tracking.
Each one of the mentioned applications is big enough to be pursued as master or doctoral theses. But we want to be engineers, not researchers! So, there is no need to dive into the details. The best way for us to cover the topics is to read review papers. I also recommend watching Cyrill Stachniss YouTube videos for geometric topics, and this series of videos from Georgia Tech University for both geometric and semantic topics.
Coding
Computer vision algorithms are often heavy and embedded boards are often resource-constrained. We need a programming language that runs fast. The C language is very fast and close to the hardware but it is often used for developing operating systems or bare-metal programming. C++ is almost a superset of C that adds object-oriented programming as well as templates, smart pointers, and many different containers. So, C++ allows us to write fast codes that are portable, more maintainable, and more memory efficient. The fact that C++ is better suited than C is approved by the migration of OpenCV 1.x from C to OpenCV 2.x (and above versions) to C++.
There is no doubt that C++ is very powerful. But it is also hard to master. So hard that you might give up, especially if you come from Python or Matlab. If you want to be a real C++ coder, follow these steps one by one:
- Get rid of Windows and install a Linux distro (preferably Debian). Learn basic Linux terminal commands. There are good videos for this on Lynda.com
- Start learning the basics of C++ from Bill Weinman in Lynda.com and get your hands dirty with C++ codes.
- Watch this series of videos from Cyrill Stachniss lab. I highly recommend this as a start for modern C++ (we call C++11 and above versions modern C++)
- Watch C++ advanced topics from Bill Winman in Lynda.com
- Read my posts (1, 2, 3, 4) to learn how to write fast C++ codes for computer vision tasks
- Check source codes of famous libraries like OpenCV, Tensorflow, or Pytorch to learn design patterns and naming conventions.
- Watch Chandler Carruth’s videos on YouTube
- Subscribe to the CppCon YouTube channel
Hardware
What makes us different from a computer vision engineer, is our insight into computer and camera architectures. We should be able to select appropriate processors and cameras for a given project. During recent years, I have come across these topics by watching several YouTube videos that explain the basics of CPUs, GPUs, TPUs, DSPs, and FPGAs. The computer architecture book from Dave Peterson is also a great reference for this. For getting informed about the future trends of computer architecture, subscribe to Coreteks and Gary Explains YouTube channels. And last, to get the latest news about single board computers, subscribe to Explaining Computers YouTube channel.
How to get jobs?
There are lots of job opportunities for an embedded computer vision engineer. Just check the “Career” page of companies that make drones, autonomous cars, or UGVs. Send your CV and wait for their response. Having sample codes in your GitHub repo increases your acceptance chance. Once invited to an interview, ask the HR to explain you the interview process. He/She is on your side and likes to hear your acceptance. During the interview, avoid talking about things that you have not worked with them before. The recruiter may ask you more on that and you will probably stuck or lie which feels really bad! Also, ask about the technologies they use in their daily works, the diversity of the people, and other stuff that are important for you. Recruiters don’t like to be the only ones that ask questions. They interview many people every day and prefer curious guys over passive ones!
What else?
Find active guys and teams on LinkedIn. Follow them to get informed about the latest news, trends, and tutorials. Share your knowledge and enjoy helping others :)
Related Posts:
- In praise of ROS
- Monocular Forward Collision Warning System
- Advanced tips to optimize c++ codes for computer vision tasks (I): Memory Management
- Advanced tips to optimize C++ codes for computer vision tasks (III): Parallel Processing
- Advanced tips to optimize C++ codes for computer vision tasks (II): SIMD
Leave a Reply
Want to join the discussion?Feel free to contribute!