Simple tips for optimizing C++ codes
When I was coding in Matlab, there were some techniques to boost the execution time. Predefining the matrix size, using vectorization and importing C codes via Matlab Executable (.MEX) files were some of the well-known solutions. Similar solutions exist for Python codes. But the story is somewhat different with C++. This comes from the fact that C++ is much closer to hardware and opens a wider control area to the programmer. This post will cover some simple, yet important, tips to accelerate your C++ code on CPU.

Optimization is often in conflict with code readability. It is strongly recommended to use a profiler first, and then optimize the most critical parts of your code. Don’t optimize every block/function just because you think it will accelerate your code.
OK. Let’s see how can we achieve faster run times …
Variables and datatypes
Use the smallest datatype that fits your application. This means that short int is better than int. intis better than float and float is better than double. But don’t forget the overflow of each type. You can’t compute the factorial of x by defining a function which uses int. It can do that only if x<=12. Higher values lead to wrong outputs.
Also, provide the maximum information about your variable to the compiler. A const variable is treated much more efficiently than a regular variable. unsigned numbers are divided faster with a constant than signed numbers.
Whenever a container is needed, if the size is small and constant, use static arrays. If the size is large (e.g. in image processing applications) use dynamic arrays, and finally, if the size might change, use vector. Static arrays are allocated on stack which is accessed much faster than dynamic arrays or vectors that are allocated on heap. This is exactly why the old C style fashion of character array is superior over string when efficiency is important. But bear in mind that static arrays are limited in size due to the limitation of stack (usually ~1-2Mb). For example, defining an int array of 1000*1000 size requires around 4Mb which may overflows the stack and lead to crash in Windows, or “Segmentation fault” error in Linux. If you decided to go with vector, make sure to use reserve before the loops. It reserves some space in memory and reduces the number of times that dynamic allocation is called in functions like push_back.
In case of variable scope, locals are accessed faster than globals. You can remove a global variable by passing it as a function argument. If it is a complex or large size variables, it might be faster to calculate it inside the function instead of passing it as an argument. You can also use static keyword for variables that are constant. It ensures that the variable is calculated only the first time that the function is called (an not in every call).
Functions
Functions add overhead in general. But they are inevitable in big projects. To reduce the calling and argument passing overheads, write them as short as possible. This increases their chance to be inlined by the compiler. If inlined, the overhead of calling is removed and the compiler can produce more optimized code. Another point is that instead of passing a vector (or generally any other container) directly, try to pass its pointer or reference. Otherwise, that function starts by copying that container which is time-consuming itself.
Conditions
When using a combination of && conditions, put the most rejectable condition as the first one, and the most acceptable condition as the last one. The reverse is true for ||conditions.
Loops
A loop will run faster when 1) the iterator is unsigned and 2) the iteration number is const. Optimizing nested loops must start in the most inner loop. Avoid calling functions in the inner loops. If inevitable, make your function inline. Also, there is a concept named loop unrolling which reduces the number of iterations by manually repeating the same instruction in each iteration. This reduces the loop overhead. For example, the following code:
for (unsgined int i = 0; i < 20; i++)
{
if (i % 2 == 0)
{
FuncA(i);
}
else
{
FuncB(i);
}
FuncC(i);
}
can be converted to:
for (unsigned i = 0; i < 20; i += 2)
{
FuncA(i);
FuncC(i);
FuncB(i+1);
FuncC(i+1);
}
which is clearly faster to execute.
If iterations are independent of each other, you can simply parallelize your loop via directive based libraries like OpenMP or OpenACC.
SIMD
It is the acronym for Single Instruction Multiple Data. In short, it is a concept in which four e.g. 8bit data (like char) are processed simultaneously in a 32bit processor. In the early days, the programmer had to implement it in Assembly but later some C intrinsics were introduced by different CPU manufacturers. Intel has SSE and AVX, ARM has Neon, and AMD has 3DNow! Using these intrinsics requires a long-detailed tutorial which I may cover later. Today’s compiler (like GNU and Clang) can automatically vectorize some simple parts of your code if you provide the proper compile flags (e.g. -O3 in GNU).
Obviously, using short int instead of int will result in faster code because the co-processor can vectorize more 16bit data than 32bit data. The same holds for float and double. This is another reason why you must use the smallest datatype that fits your application.
How much they can speed up?
To prove the impact of the mentioned tips, an optimized code was compared to a non-optimized version on Raspberry Pi 3 B+ running Raspbian Jessie with g++ 4.9 compiler.
The first code is a simple script for calculating the L2-norm of two vectors without considering optimization tips:
#include <iostream>
#include <vector>
#include <math.h>
#include <time.h>
using namespace std;
vector<double> calc_norm(vector<double> input_a, vector<double> input_b)
{
vector<double> output_c;
for(int i=0;i<input_a.size();i++)
output_c.push_back(sqrt(pow(input_a[i],2) + pow(input_b[i],2)));
return output_c;
}
int main()
{
int n = 1000;
vector<double> a(n,5);
vector<double> b(n,7);
vector<double> c;
clock_t start = clock();
for (int i=0;i<100;i++)
c = calc_norm(a,b);
clock_t finish = clock();
cout << 1000*(finish-start)/CLOCKS_PER_SEC << endl;
return 0;
}
And the second code is the optimized version of the same script:
#include <iostream>
#include <math.h>
#include <time.h>
inline void calc_norm(const int *input_a, const int *input_b, const unsigned int n, float *output_c)
{
for(unsigned int i=0;i<n;i++)
output_c[i] = sqrtf(input_a[i]*input_a[i] + input_b[i]*input_b[i]);
}
using namespace std;
int main()
{
const unsigned int n = 1000;
int a[n]; std::fill(a, a + n, 5);
int b[n]; std::fill(b, b + n, 7);
float c[n];
clock_t start = clock();
for (unsigned int i=0;i<100;i++)
calc_norm(a,b,n,c);
clock_t finish = clock();
cout << 1000*(finish-start)/CLOCKS_PER_SEC << endl;
return 0;
}
Using arrays instead of vectors, int instead of double, the float sqrtf instead of the double sqrt, the simple multiplication instead of calling pow(x,2)inside a loop, and passing pointer to function instead of the container itself, all resulted in a considerable boost which is shown below. I also compared the effect of using optimization flag.
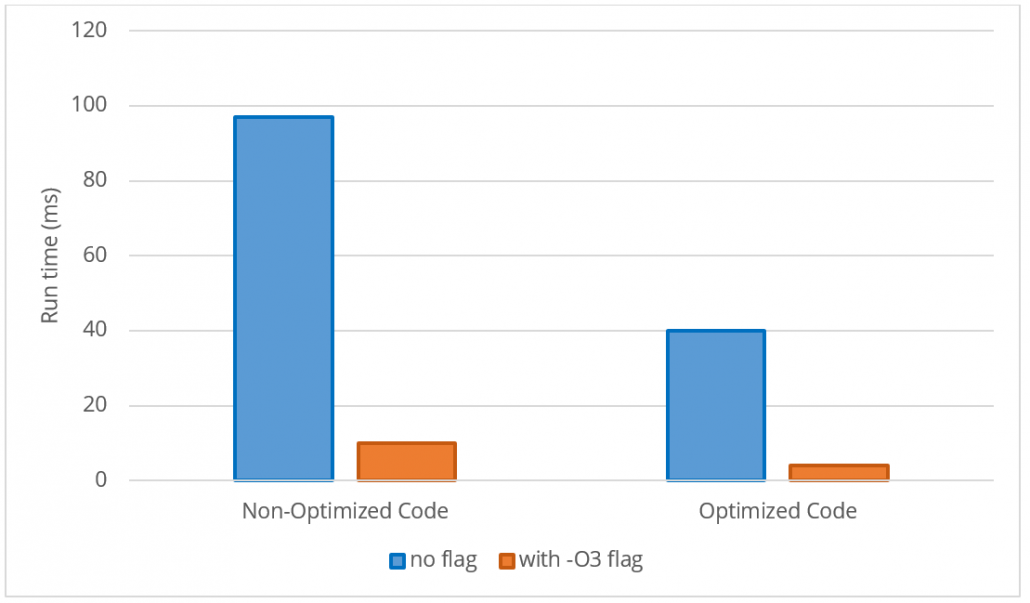
Further notes
1. The tips I mentioned here were the simple widely-used techniques that you can also see in the source codes of fast libraries like OpenCV. If you are interested in more tips and detailed explanations, read Agner Fog’s optimization manual.
2. Optimization is not just about your source code. Sometimes using a more efficient Operating System can help. You may prefer to minimize the OS overhead by using Real Time Operating Systems (RTOS) instead of High Level Operating Systems (HLOS) like Windows/Linux, or totally remove the OS overhead by doing Bare-Metal programming. Sometimes you have to sweitch to other processors that are built for doing specific tasks faster than a CPU. For example, a DSP might be more optimized for signal and image processing due to its faster arithmetic units. A GPU is certainly faster for parallelized tasks and an FPGA is the best option if high speed with low power-consumption is desired. Using such processors is a whole different story. I may later cover them but for now, check OpenCL.
Leave a Reply
Want to join the discussion?Feel free to contribute!
Leave a Reply
Related Posts:
- Advanced tips to optimize C++ codes for computer vision tasks (III): Parallel Processing
- Image classification with pre-trained models using libtorch (Pytorch C++ API)
- Hands on QR Code detection
- Advanced tips to optimize C++ codes for computer vision tasks (II): SIMD
- Advanced tips to optimize c++ codes for computer vision tasks (I): Memory Management
hello, could you recommend me a profiler? it’s better if it is well visualized.
Sure. You can use linux’s perf tool. And I know that CLion can visualize the results.
thank you.