Transfer learning for face mask recognition using libtorch (Pytorch C++ API)
In the previous post, we learned how to load a pre-trained model in libtorch and classify images with them. But real-world applications often include objects which are not necessarily inside ImageNet dataset. We need a network to classify our custom targets. In this tutorial, we will use transfer learning to fine-tune Resnet18 for face mask recognition. The code for this series of libtorch posts can be found here.
1. Why transfer learning?
Training a deep neural network from scratch is known to be a very data-hungry and time-consuming task. Hyper-parameters must be initialized well and the training must run on a high-end GPU (sometimes multiple GPUs). A simpler solution is to use a pre-trained network for feature extraction and a custom fully-connected (FC) layer for classification. This technique is known as transfer-learning. Obviously, training that FC layer requires much less time and data compared to training the whole network. So, if you don’t have thousands of images or powerful GPUs, then go with transfer-learning.
2. Face mask recognition
It has been proven that wearing face masks can effectively reduce Covid-19 transmission risk. One potential application of computer vision is to use security cameras to recognize people who don’t use masks. To do this, we need a set of face images without mask (I call them raw faces) and a set of face images with mask (I call them masked faces) to train a CNN. RMFD is a good dataset for this task which can be downloaded here.
3. Loading data
Libtorch has built-in classes to load popular datasets such as MNIST. These classes are all inherited from a base class: torch::data::datasets::Dataset. We can make a custom class for RMFD data by inheriting from the base class and overriding its functions:
class RMFD : public torch::data::datasets::Dataset<RMFD>
{
private:
std::vector<torch::Tensor> images, labels;
size_t ds_size;
void load_data(const std::string& folderName, const int label);
public:
// Constructor
RMFD(const std::string& rawFaceFolder, const std::string& maskedFaceFolder);
// Override get() function to return tensor at location index
torch::data::Example<> get(size_t index) override;
// Returns the length of data
torch::optional<size_t> size() const override;
};
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
RMFD::RMFD(const std::string& rawFaceFolder, const std::string& maskedFaceFolder)
{
std::cout << "Loading Data..." << std::endl;
load_data(rawFaceFolder, 0);
load_data(maskedFaceFolder, 1);
ds_size = labels.size();
std::cout << "Data Loaded Successfully" << std::endl;
}
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
void RMFD::load_data(const std::string& folderName, const int label)
{
const std::vector<std::string> persons = listFolders(folderName);
const int numPersons = persons.size();
for (const auto& person : persons)
{
std::vector<std::string> imageNames = listContents(person, {".jpg", ".png", ".jpeg"});
if (!imageNames.size()==0)
{
images.push_back(read_image(imageNames[0]));
labels.push_back(read_label(label));
}
}
}
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
torch::data::Example<> RMFD::get(size_t index)
{
torch::Tensor sample_img = images.at(index);
torch::Tensor sample_label = labels.at(index);
return {sample_img.clone(), sample_label.clone()};
}
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
torch::optional<size_t> RMFD::size() const
{
return ds_size;
}
4. Training
Given a pre-trained feature extractor, we can make our face mask recognizer by training a custom fully-connected layer. In this tutorial, I used Resnet18 for feature extraction. Since training is not performed on the network, gradients are set to False and the network is set to eval() mode. The default fully-connected layer is removed and a random data is fed to the network. Finally, the JIT traced model is saved (to be later loaded in train.cpp code).
import torch
import torchvision
# An instance of your model.
model = torchvision.models.resnet18(pretrained=True)
# Set upgrading the gradients to False
for param in model.parameters():
param.requires_grad = False
model.eval()
# Save the model except the final FC Layer
resnet18 = torch.nn.Sequential(*list(model.children())[:-1])
# An example input you would normally provide to your model's forward() method.
example = torch.rand(1, 3, 224, 224)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing.
traced_script_module = torch.jit.trace(resnet18, example)
traced_script_module.save("traced_resnet_without_last_layer.pt")
In the train.cpp code, we first use a data loader to generate batches of size 4 from RMFD data. Data is loaded in a random pattern and if the number of training images is not a multiple of the batch size, the last batch is dropped to avoid a crash in training.
string rawFaceFolder = argv[1]; string maskedFaceFolder = argv[2]; auto train_dataset = RMFD(rawFaceFolder, maskedFaceFolder).map(torch::data::transforms::Stack<>()); const size_t train_dataset_size = train_dataset.size().value(); int batch_size = 4; auto train_data_loader = torch::data::make_data_loader(std::move(train_dataset), torch::data::DataLoaderOptions().batch_size(batch_size).drop_last(true));
Then we load the JIT traced model and define our custom fully-connected layer. Resnet18 produces 512 features. Our FC layer must map these features into two classes (raw face vs masked face). So we need a 512×2 layer. The parameters of this layer are passed to an Adam optimizer with a learning rate of 1e-3. Given the resnet18 feature extractor, our 512×2 linear layer, the optimizer parameters, and the data loader, we are now ready to start the training. In each epoch, the data loader loads a batch of images and labels. The images are fed to the feature extractor, followed by the linear-layer. The loss function is defined as the number of mismatches between the produced labels and the actual labels. The optimizer is then called to refine the linear-layer. The next batch of data is loaded and the whole procedure is repeated. At the end of each epoch, the average accuracy and loss are printed. If the accuracy would be better than the previous epoch, then the linear-layer is saved. With 940 samples of raw and masked faces, it took about 5 minutes to achieve 98% accuracy in just 5 epochs.
int main(int argc, char* argv[])
{
//data loader code
auto model = torch::jit::load(argv[3]);
torch::nn::Linear linear_layer(512, 2);
torch::optim::Adam optimizer(linear_layer->parameters(), torch::optim::AdamOptions(1e-3));
train(model, linear_layer, train_data_loader, optimizer, train_dataset_size);
return 0;
}
template<typename Dataloader>
void train(torch::jit::script::Module net, torch::nn::Linear& lin, Dataloader& data_loader, torch::optim::Optimizer& optimizer, size_t dataset_size)
{
float best_accuracy = 0.0f;
net.eval();
for(int epoch=0; epoch<5; epoch++)
{
float mse = 0.0f;
float Acc = 0.0f;
int batch_index = 0;
for(auto& batch: *data_loader)
{
auto data = batch.data;
auto target = batch.target.squeeze();
optimizer.zero_grad();
vector<torch::jit::IValue> input;
input.push_back(data);
auto output = net.forward(input).toTensor();
output = output.view({output.size(0), -1});
output = lin(output);
auto loss = torch::nll_loss(torch::log_softmax(output, 1), target);
loss.backward();
optimizer.step();
auto acc = output.argmax(1).eq(target).sum();
Acc += acc.template item<float>();
mse += loss.template item<float>();
batch_index++;
}
float MSE = mse/batch_index; // Take mean of loss
float Accuracy = Acc/dataset_size;
cout << "Accuracy: " << Accuracy << ", " << "MSE: " << MSE << endl;
if (Accuracy > best_accuracy)
{
best_accuracy = Accuracy;
cout << "Saving model" << endl;
torch::save(lin, "model_linear.pt");
}
}
}
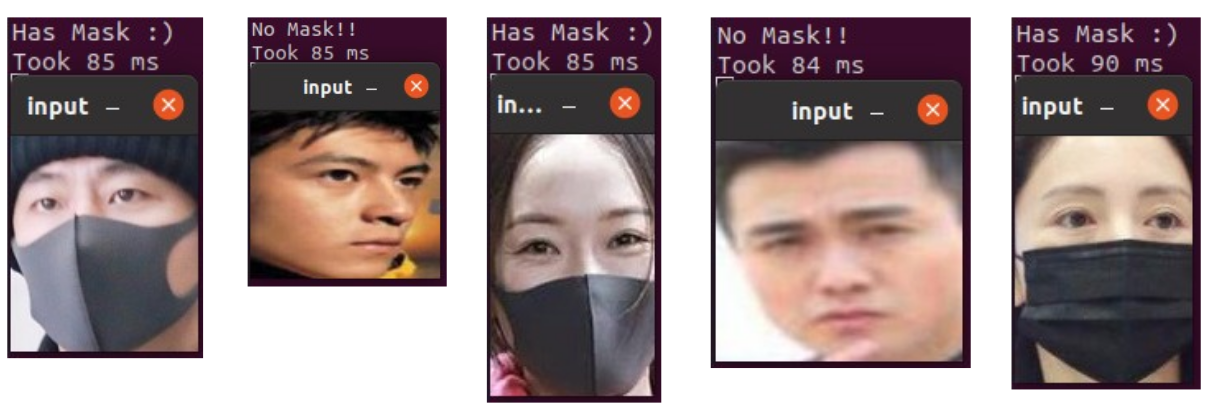
5. Classification
Let’s give some new images and test our classifier. We load the feature extractor and the trained linear-layer. Results are satisfying :)
#include "utils.hpp"
#include <torch/script.h>
#include <chrono>
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
int classify_image(const std::string& imageName, torch::jit::script::Module& model, torch::nn::Linear& linear_layer)
{
torch::Tensor img_tensor = read_image(imageName);
img_tensor.unsqueeze_(0);
std::vector<torch::jit::IValue> input;
input.push_back(img_tensor);
torch::Tensor temp = model.forward(input).toTensor();
temp = temp.view({temp.size(0), -1});
temp = linear_layer(temp);
temp = temp.argmax(1);
return *temp.data_ptr<long>();
}
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
int main(int argc, char* argv[])
{
if (argc!=4)
throw std::runtime_error("Usage: ./exe imageName modelWithoutLastLayer trainedLinearLayer");
torch::jit::script::Module model;
model = torch::jit::load(argv[2]);
model.eval();
torch::nn::Linear linear_layer(512, 2);
torch::load(linear_layer, argv[3]);
std::cout << "Model loaded" << std::endl;
auto t1 = std::chrono::high_resolution_clock::now();
int result = classify_image(argv[1], model, linear_layer);
auto t2 = std::chrono::high_resolution_clock::now();
int duration = std::chrono::duration_cast( t2 - t1 ).count();
if (result==0)
std::cout << "No Mask!!" << std::endl;
else
std::cout << "Has Mask :)" << std::endl;
std::cout << "Took " << duration << " ms" << std::endl;
cv::Mat img = cv::imread(argv[1]);
cv::imshow("input",img);
cv::waitKey(0);
return 0;
}
Leave a Reply
Want to join the discussion?Feel free to contribute!